tl;dr: We crawled, through a cool hacky method, the (legally available) user data for 20 million users in SoundCloud. Then we proceeded to do some simple data analysis on it and made some cool graphs you can see below. Furthermore, we successfully used K-Means clustering to find spam accounts and we used that information to train a Neural Network for future spam prediction. Lastly, we provide some more insight into were this spam is coming from and how it is engaging with the community. Most importantly, at the end of this write-up you will find our dataset, slides, formal paper, and code repo.
I love SoundCloud, I really do. It has become almost a monthly ritual to just randomly surf through it and find musical nuggets of gold. Whether it be remixes, originals, acoustic covers, etc. there's always something fun to find there. And since I don't listen to radio, SoundCloud is one of my main sources of new music. However, I don't only like SoundCloud from a pure consumer standpoint, but I also like it as a developer.
For those that might not be aware, SoundCloud is one few musical services of it's type that provides a really open API for developers like myself to engage with. While its true that the API is a bit rough in some places, at the end of the day I don't know of any other music services that provide as much data as SoundCloud does.
During my time at UCSB, I've already done two projects involving this platform. Today I wanted to go into more detail about my latest project which consisted on performing Spam Analysis and Spam Clustering in SoundCloud.
As a brief note before you keep reading, I wrote this post in a rather informal narrated approach, if you want to read something a bit more formal (as you would find in an academic journal) then scroll down and read the actual paper (or check it out at academia.com)
* Follow me for more hacking content! Follow @konukoii
Overview
The main idea for this project started when, during one of my music discovery sessions, I received a random notification saying that a scantly clad woman called Caitlin Reed had started following me. I clicked on the notification and it took me to Catlin's profile which featured a cover picture of her naked and a very welcoming description saying: "Good girls do bad things sometimes! Hi! Delightful, do you want to see me naked boobs?" followed by a bit.ly link. I chuckled a bit and then something in the back of my mind clicked: Spam in SoundCloud? That's so weird. The platform is rather limited in how users can interact with each other, so how does spam work here? Furthermore, how much of it is out there? And with that this project was born.
You could visualize this project as a three part endeavor:
- Collect as much user data from SoundCloud as possible.
- Analyse spam incidence. Define types of spam. What do they do and how they interact?
- Using ML could we help predict or distinguish spam users accurately. What are the most important distinguishing factors?
Part 1: The Crawling
Crawling was my favorite part, and potentially the one with the most hacking involved. Since we only had a couple of weeks and SoundCloud has more than 40 million users, we wanted to build a really fast heavy-duty crawler that could get us the most user data as quick as possible. We started by building the basic python crawler using requests and while probing around we discovered that user id's were assigned in sequential order. This was great! However, immediately we ran into our first big problem: Getting the API key. It turns out that recently SoundCloud decided to limit the API keys it gives out; You have to fill a form and wait for a couple weeks (almost 6 weeks in our case) for them to assign you one. Since we didn't have much time, we decided to peek under the hood (shout-out to Burp and Chrome devtools) and see what the actual website did to retrieve user information. What a big surprise we got when we found that the SoundCloud website simply used the same API except they had 1 static "public" API key. (Something tells me you guys shouldn't be doing this. Perhaps use cookies or short lived temp keys.) Bingo! We "borrowed" this temporarily and we could now crawl limitless and as a side effect "anonymously" (I guess they could still track our IPs tho.)
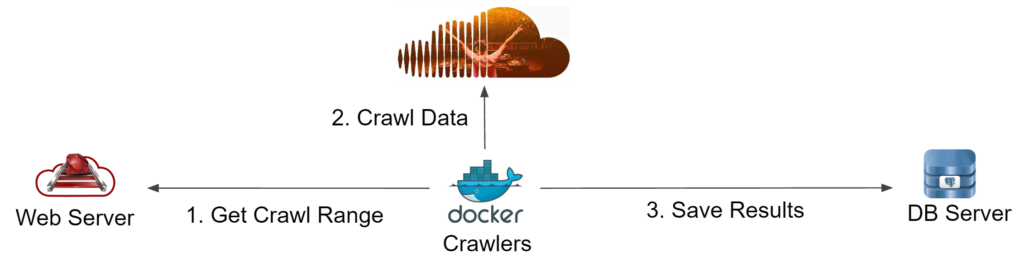
Now that we had the keys to the castle, the other problem was scaling this small crawler into a mammoth crawling machine. We decided that Docker was the way to go for this. If you haven't heard about Docker, you can think of it as a very lightweight Virtual Machines with which you can wrap your app and deploy a ton of them anywhere. With this beast, we started running 20 containers on a single machine (plain ol' computer) and we could get around 1,000 users/hour. Of course, now there is a third problem: How do we manage all the crawlers so that we aren't crawling repeated ranges and whatnot. We decided to build an external server that would issue random ranges of 1000 users to crawl. So in the end, each crawler would ask the external server for a range to crawl, proceed to crawl it, and finally return the data to an SQL database.
With this beast running for a couple of weeks on two computers we managed to obtained about 20 Million Users. One final observation is that these 20 million users were randomly and evenly spread throughout the entire user range.
Part 2: Data Analysis
I'm not gonna lie, we were lost with all this data, and our original goal of finding spam seemed extremely daunting cause we had very little knowledge on how to apply ML to solve a problem like. We decided that our best approach was to first familiarize ourselves with the data, understand how people engage with the platform, and find any actual examples of spam. We were rather amused by the many things we found and, as such, here are some of the questions we asked ourselves in the process of better understanding the community of users.
How many people pay for subscriptions? (Not including their new service: SoundCloud Go)
| Subscription Plan | % of Users |
| Free | 99.798 |
| Pro Plus | 0.142 |
| Pro | 0.060 |
We were rather surprised that so few users actually paid for the Pro and Pro Plus subscriptions. We also found one single user that had a "Solo" plan. We didn't know if "Solo" was an error in their database or perhaps a super hidden subscription program that only really cool people get. Psst...I'm cool too man!
How many people actually generate content?
| Track Count | % of Users |
| 0 | 92.810 |
| 0 - 10 | 6.0189 |
| 11 - 100 | 1.1546 |
| 101 - 500 | 0.0154 |
| 501 - 1000 | 0.0010 |
| 1001+ | 0.0011 |
Amazing to think that its essentially 7.2% of the community what is driving SoundCloud. I am happy to add that I'm in that 7.2%
How do users engage with each other in the platform?
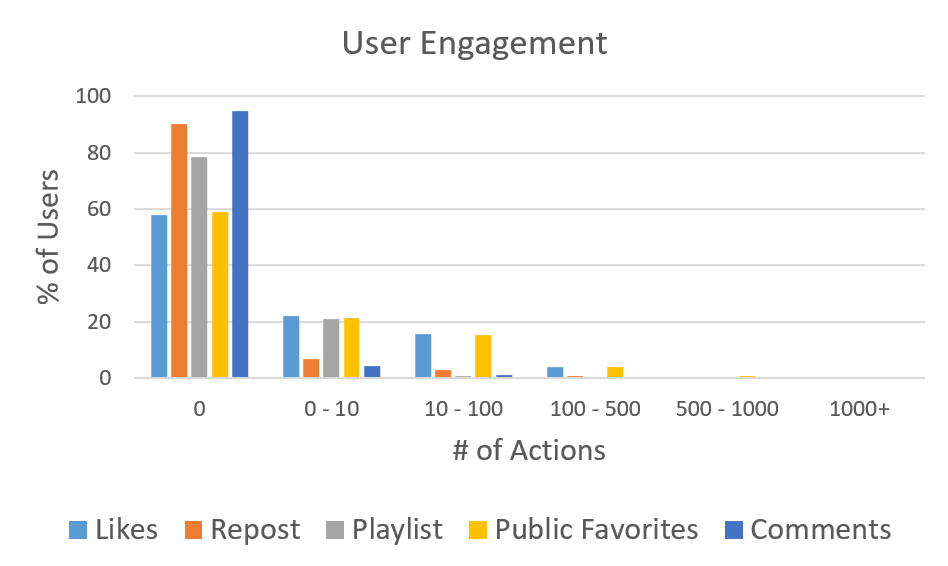
This graph shows that most users have actually never "engaged" (aka. commented, liked, favorited, playlisted or reposted) with the community. It does not account for tracks listened, so people could essentially be using it only to listen to music and not really leaving likes, comments, etc.
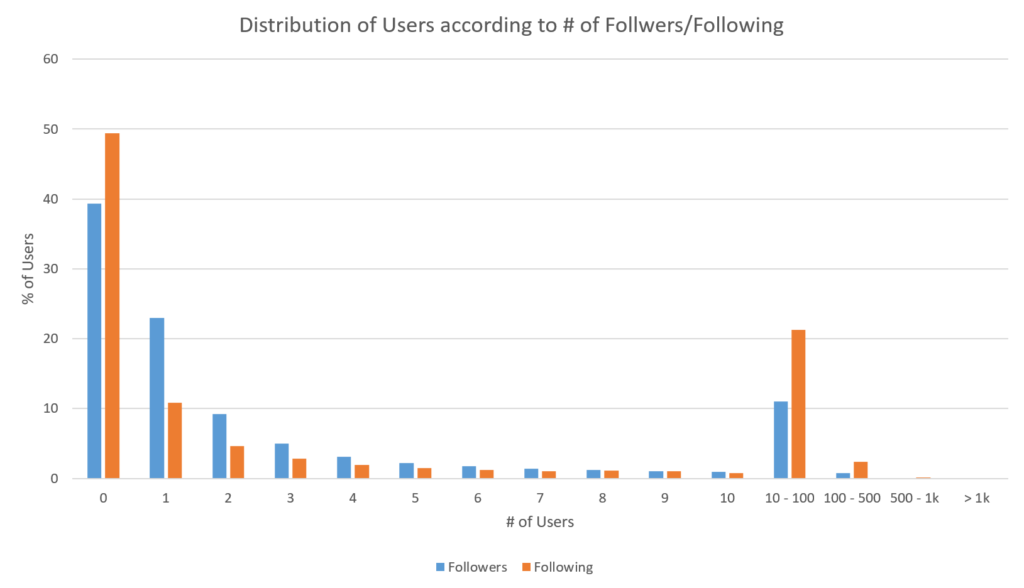
How do the followers, following relationships look like?
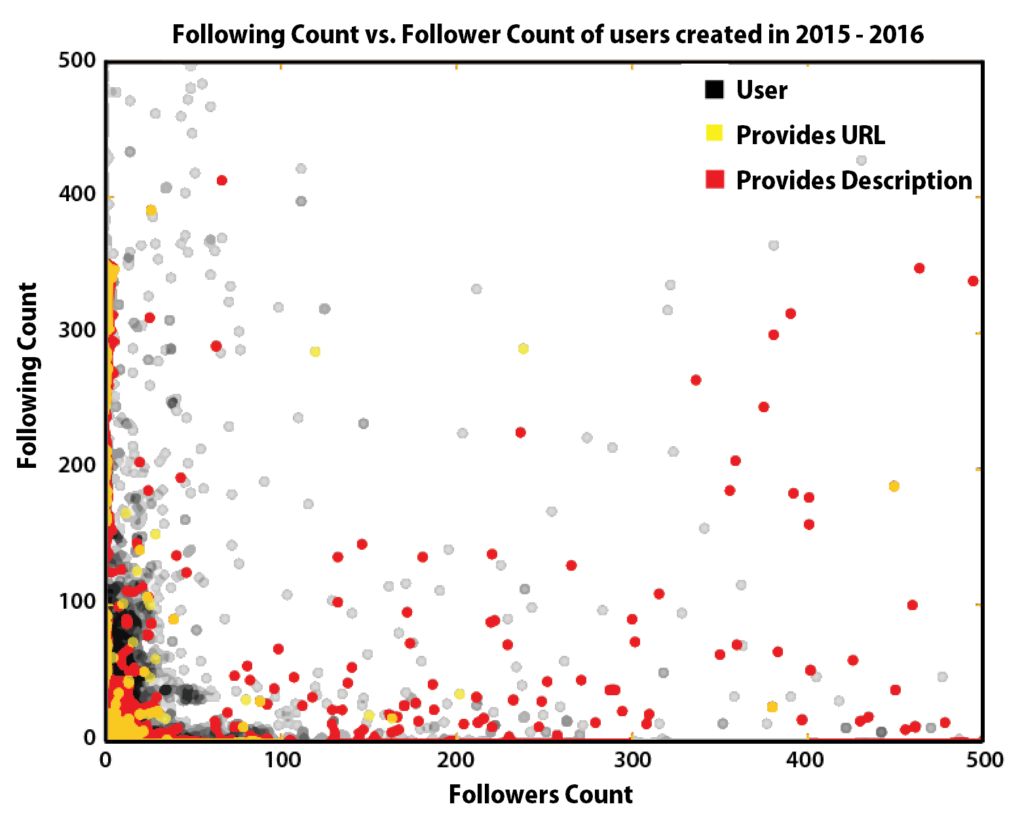
This graph is fun cause it shows the separation between fans and artists. The more the user is to the right, the more it is a prominent artist. The more it is towards the top, the more it is a "super" fan. However, unsurprisingly we still have a bunch of people clustered at 0,0. With this graph we actually struck gold and found some spam. We noticed a strange large group of people that followed 250-350 people, but no people following them. Once we looked closer we found them all to be spam users.
How many users share links and where are they pointing?

We took a look at what web links users shared to, since most spam will attempt to redirect traffic to specific websites. Through this we found that most spam users could easily be detected by whether or not they used a URL shortner (goo-gl, bit-ly, tinyurl-com)
Feature Selection
Finally, after we had a better understanding of the data we decided to represent each user by the following features:
- # of Followers
- # of Following
- # of Published Tracks
- Is URL Provided?
- # of Profanities in Description
- # of Profanities in URL Title
- # of Duplicate Descriptions (users using the same description)
- # of Duplicate URLs (users using the same URLs)
- Activity (Likes + Reposts + Playlist + Comments + Favorites)
- Type of Subscription
- Is URL a URL Shortner?
Using Cluster Analysis and Correlation-Based Feature Subset were able to drop "Subscription Type", "# of Duplicate URLs", and "# of Profanities in URL Title" as being useless features.
Part 3: Machine Learning for Clustering and Spam Prediction
Once we had probed our dataset, gotten an idea of how users interacted, found some ground proof for spam users, and designed a feature vector with which to represent users, we were ready to do some ML. Initially we decided to use our data to build clusters. This would allow us graph and partition our users such that we could find spam close to our ground truths that we had missed.
K-Means Clustering
We ran the latest year worth of data through a batched K-Means cluster and found plenty of more spam that we had initially missed. Initially we did not force the algorithm to return a specific number of k clusters; Instead, we used the Elbow Method to determine that the best k equaled either 4 or 5 clusters.
Furthermore, upon closer inspection and parameter fine-tuning we realized our Clustering algorithm was running with impressive accuracy, creating groups that closely resembled in nature. Below you can better see the results we obtained when we ran a subset of 7M users.

Neural Network
Lastly, inspired by my other NN project, I decided to code a simple Feed-Forward Neural Network using Keras. I trained it on an evenly split 10,000 user dataset containing Superstars, Fans, Regular Musicians, and Spam. Then I randomly tested it against 10,000 other users (again evenly split) and found a test accuracy of 85%.
To give it a nice touch we bundled all of this up in a Flask Container and created a small website that we were hosting at soundcloud.pw and soundcloud.space. (Yep, I own those, ain't that cool?)

Types of Spam
In total we found about 10,000 spam user accounts. We did notice a lot of dead user ids, which were most likely spam users themselves that got erased by SoundCloud. Among those spam accounts we found two big main types of spam:
Pornographic Spam: The biggest group of spam was pornography related spam. It essentially presented profane description, with re-used imagery and names taken from other social sites, and pointed to pornographic websites using url shortners. We found that most shortners redirected to websites that themselves redirected to a final porn site destination.
The two most common sites were mrbtrack(dot)com and super-goood(dot)ru; Both which were registered in Russia and hosted in Russia and Germany respectively. Furthermore, we also found a group of sites which shared a similar pattern of 9 random letters and always finished with an African top level domain (eg. sungzkfpm(dot)ga). Unsurprisingly, all these were created in 2016 and used WhoisGuard.
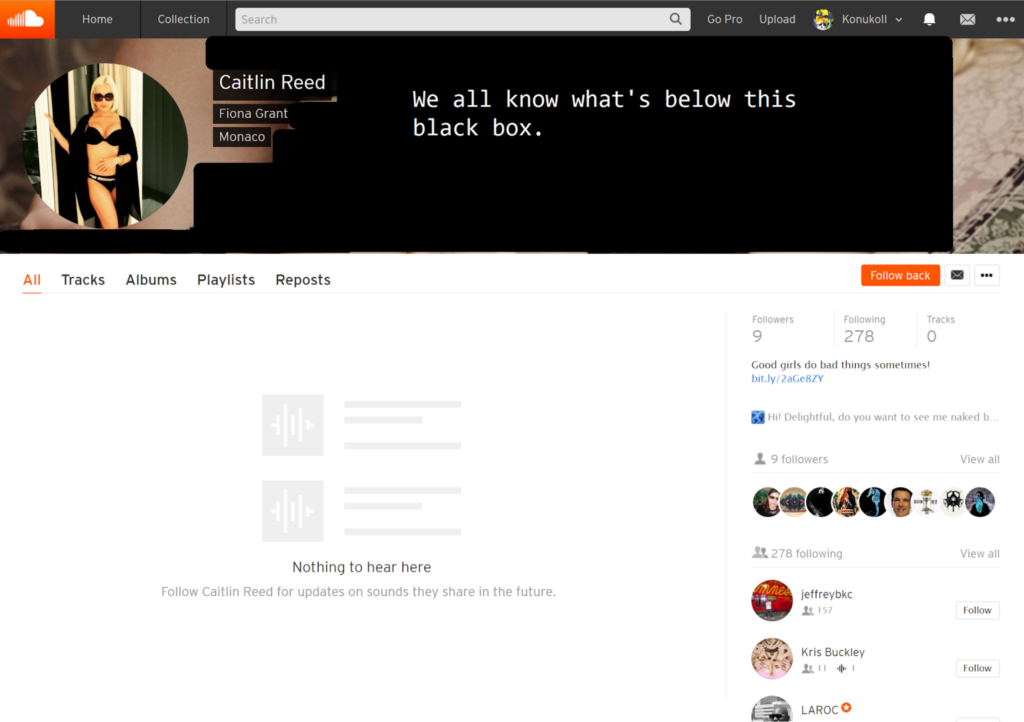
"Fake" Spam: We had a very hard time describing and finding this type of spam, since this spam closely resembled legitimate users. Their descriptions were randomly created by concatenating short phrases such as "Coffee Addict", "Twitter Enthusiast", "Passionate Food Lover", etc. They seemed to be created in batches as we found a couple that were created at the same time, shared the same description, but held different names.
However, we have yet to understand the purpose of this "fake" spam, seeing as they interact in no way with the community and they do not share a description or link.

(Bonus!) SEO leaches: While not all necessarily spam, we did want to point out we found a vast group of businesses and people using the platform in rather unconventional ways. We found everything from plumbers, oil rig defense attorneys, wedding photographers, and other professionals creating accounts to "promote" their business. Some even went as far as creating multiple duplicate accounts.
Final Comments & Links
As always feel free to contact me with any questions, suggestions, or further ideas. We also want to extend an apology to SoundCloud for doing non-stop queries on their servers :P (We did noticed you changed your public api key towards the end of the project, and we chose to stop at that point). Below is the link to the dataset we gathered so you can do some analysis of your own if you wish.
Repository: https://github.com/pmsosa/CS276-Project
Paper: https://www.academia.edu/30883075/Soundcloud_Spam_Analysis
Dataset: http://konukoii.com/files/soundcloud_user_dataset.zip