Machine Learning, AI, and other related fields have recently been surrounded by a lot of hype. Although I'm not necessarily extremely drawn to these fields this winter quarter ended up being a perfect opportunity to at least dip my feet into them. I took two classes "Data & Knowledge Bases" and "Computer Networking" which ended up being perfect platforms to do some ML studies.
I ventured into the world of ML with two projects that aimed to use Neural Networks to solve two different problems: "Twitter Sentiment Analysis" (presented on this post) and "Spam Analysis within SoundCloud" (presented on an upcoming post).
* Follow me @konukoii for more interesting content!
The "Motivation": Twitter Sentiment Analysis
While the main motivation behind this project was to learn, understand, and ultimately hand code a Neural Network, we decided to frame all of our efforts to do Twitter sentiment analysis. In other words, we were attempting to use our NN to distinguish whether any given tweet is of positive (happy, funny, etc.) or negative (angry, sad, etc.) sentiment.
The Dataset
Our dataset consisted of a huge list of roughly 1.5M tweets that had been labeled as good or bad sentiment. The dataset contained tweets labeled by the University of Michigan and Niek Sanders. Our dataset can be found here. Notice than when training and testing we simply sampled random subsets of this dataset.
The Intuition behind Neural Networks
The truth is that to best understand the inner workings of Neural Networks I would suggest checking out Nielsen's or Trask's work, because they do a fantastic job at presenting the subject. Alternatively, you can take a look at our work were we condensed all of these ideas there. However, I wanted to attempt to convey a simple understanding of how these NNs work.
An NN is essentially trying to emulate a brain. The NN will have a set of nodes (neurons) connected between each other (these connections are equivalent to synapses). The most basic NNs, called Feed-Forward NNs, have an input layer (of nodes), an output layer, and in the middle a variable number of "hidden layers". Each layer consists of a number of nodes that are fully connected to both the layers before and after them. These NNs have two possible operations: Forward Propagation and Backpropagation.
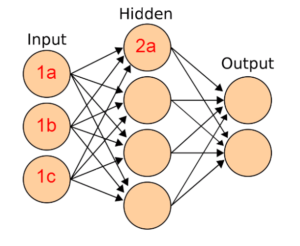
Forward Propagation is a method used to calculate the value of a node given all the previous nodes connected to it. If we focus on the picture above, The value of the 2a node is dictated by the values of 1a, 1b, 1c. Now notice that each connection will have its own weight (this is equivalent to how close the neurons are in a brain; the closer, the easier it is for a neuron to activate the other. the further, the harder it will be.)
Furthermore within the node 2a there is an activation function which essentially normalizes it's own value to something between 0 and 1 (although different activation functions can be used for different purposes.)
So the final result is that value of 2a = activation(w1(value of 1a) + w2(value of 2a) + w3(value of 1c)).
If one keeps doing this for all nodes, one can calculate the output of any given input. This is needed for both the training and testing phase, except that in the training phase a forward propagation is immediately followed by a backpropagation.
Backpropagation is a method used only during the training phase. After running the forward propagation on an NN, we calculate the error obtained between our output and our expected output and we use backpropagation to fix (or diminish) that error. Backpropagation essentially allows neurons to re-adjust their weights in such a way that given a specific input, the proper output will be returned. the exact mathematics of this are a bit convoluted so I'd rather point you to our paper to further understand the maths.
Representing Tweets
As you may have already noticed our NN accepts only numbers as inputs. Thus, we needed to find a way to represent tweets as numbers without loosing too much information. We knew that doing something simple as hashing each word wouldn't work because you loose the relation and even meaning of words. For example; Imagine HATE = 1001 and LOVE = 1000; The two words are way to similar and the NN will activate equally for both. So instead, we started tinkering around and tried 3 different methods.
Bayesian Probabilities
Our first very naive approach was very similar to applying Naive Bayes Classifier. We calculated the probabilities that each word in the dataset was good or bad and then fed that as the input to our Neural Network.
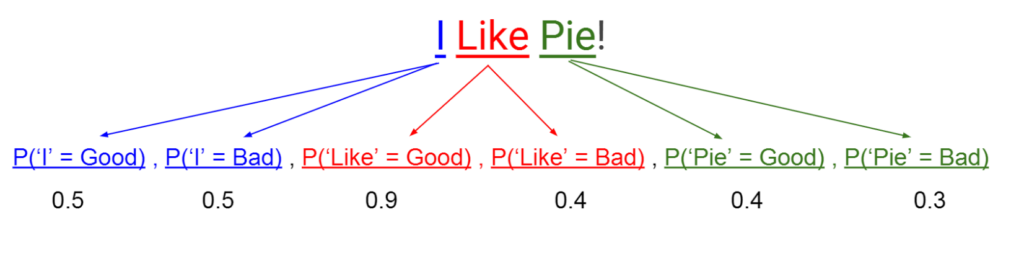
This provided results of around 63%, which were good, but not great. Futhermore, we found that it performed nearly identically to a Bayesian Classifier, which meant we were simply going a really complicated way to achieve the same results. Thus, although it was an interesting starting point, it was a rather poor tweet representation.
Word Embeddings
We heard lots of cool things about word embeddings and decided to try them out. Word Embeddings are a rather new method of describing words in a dictionary by mapping them into n-dimensional fields. The actual methodology varies depending on the authors (see wiki). In our case we used Keras' built in Word Embedding layers to build our own.
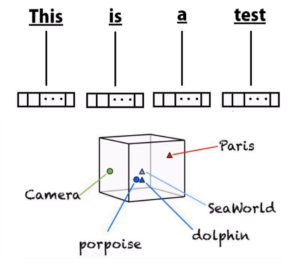
Although we originally thought this was going to give us fantastic results, we actually obtained poorer accuracy than with plain and simple Bayesian Probabilities. We realized that this happened because Tweets are very unique literal constructs where people use lots of uncommon things such as mentions (@someone), hashtags (#topic), and urls. Furthermore, typos and irregular abbreviations or lack of whitespace due to length constraints, made our word embeddings inaccurate.
Feature Vector
After our "failure" with Word Embedding, we decided to go back to the drawing board. We asked ourselves: What makes a tweet a tweet? After long philosophical contemplation, we came up with a set of features that we believed described each tweet as best as possible. We came up with a long list of features that tried to capture as much information as possible. Of course, we knew that some of these features were not as useful as others and thus, we filtered the useful ones using Correlation-Based Feature Subset Selection in WEKA. This allowed us to select only the most descriptive (and non-redundant) features from our list.
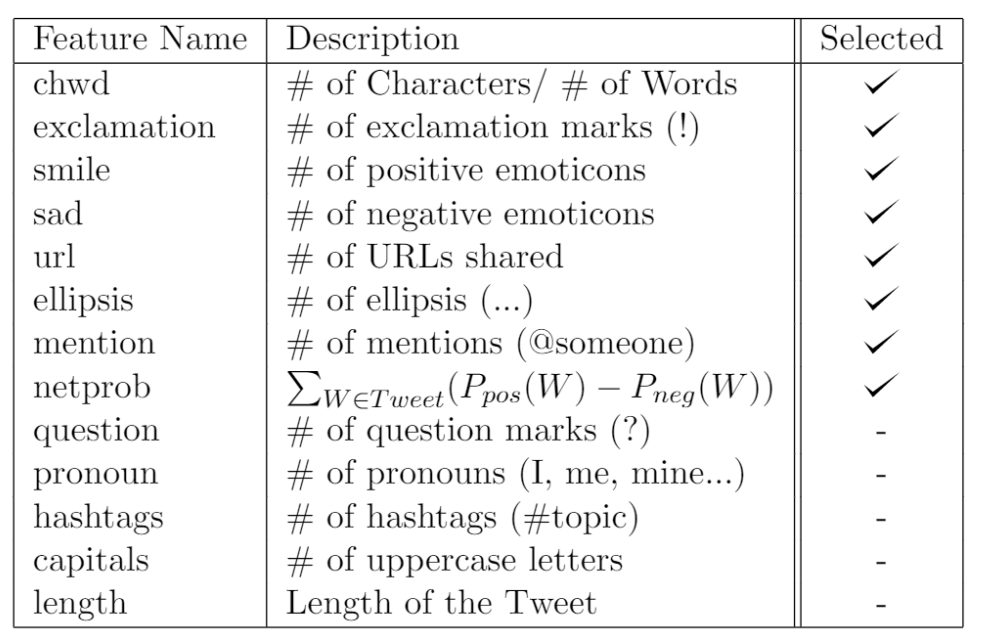
This actually provided the best results, and we were actually able to reach near 70% accuracy. We considered this to be successful seeing how it would have landed us in the top 30 of the Kaggle Michigan University Twitter Sentiment Analysis Challenge.
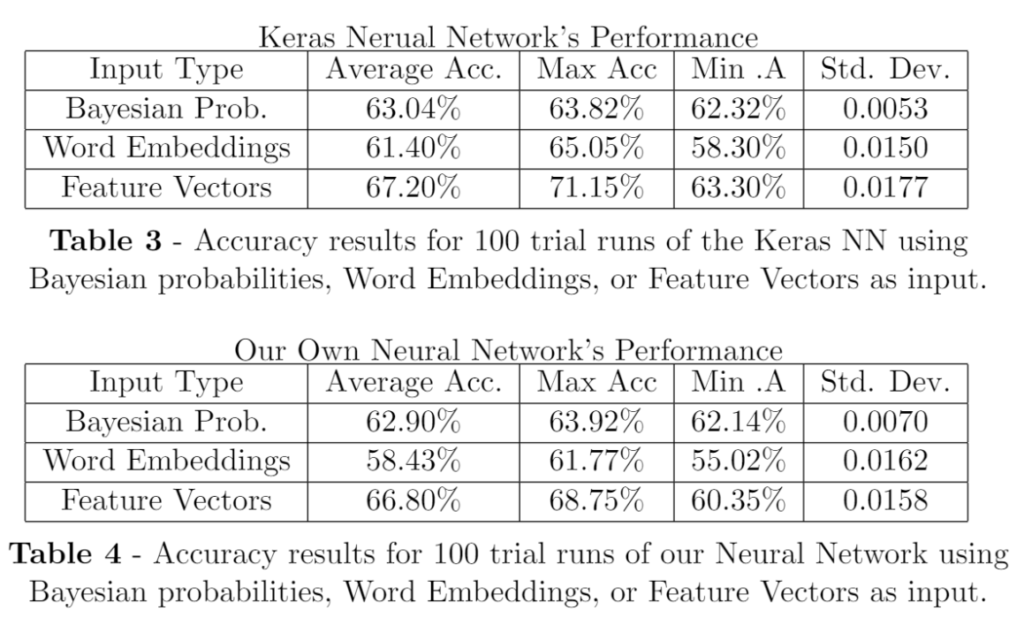
Our Results
On our experiments, we trained and tested our NN vs. an NN built using Python's Keras Library (a very popular ML library). Furthermore, we ran tests to fine tune the parameters for each NN to run at top performance. For a further interesting discussion of how each parameter affected the NNs Performance, please check out the paper below.
We found our NN to be comparable to the Keras NN, as ours was right on the heels of Keras. Here are the full results for further comparison:
The Paper & Code
Feel free to download/bookmark the paper at Academia.com and get involved with our git repo: https://github.com/pmsosa/CS273-Project.
 Loading...
Loading...
Recent Comments