A year ago I had written a paper for a Neural Networks class that I hadn't gotten around to publish. I decided to take a small break from most of my hacking posts to talk a bit about Machine Learning. This paper was a continuation of some previous work I had done (outlined in this past post) regarding Sentiment Analysis of Twitter data. (I recommend taking a look at that post if you are new to Neural Networks)
This is a shorter version of the research paper I wrote, so feel free to check that out if you want to go into more details. Also, if you only care about the implementation check out my Github project.
* Recently revived my old Twitter account. Follow me for more interesting content!
Follow @konukoii
Motivation
Twitter is now a platform that hosts about 350 million active users, which post around 500 million tweets per day! It has become a direct link between companies/organizations and their customers, and such it is being used to build branding, understand customer demands, and better communicate with them. From a data scientist point of view, Twitter is a gold mine that can be used, among a million other interesting things, for gauging customer sentiment towards a brand.
My personal stake in this project stemmed from my curiosity to better understand Neural Networks, particularly CNN and LSTMs. In a previous class, I had created simple Feed-Forward Neural Networks to solve this very problem, however I knew that my results could be substantially better when harnessing the power of more specialized networks.
Furthermore, I wanted to do something I hadn't really seen other people do and I was curious about the results of combining these two networks.
Intuition: Why CNNs and LSTMs?
Before starting, let's give a brief introduction to these networks along with a short analysis of why I thought they would benefit my sentiment analysis task.
CNNs
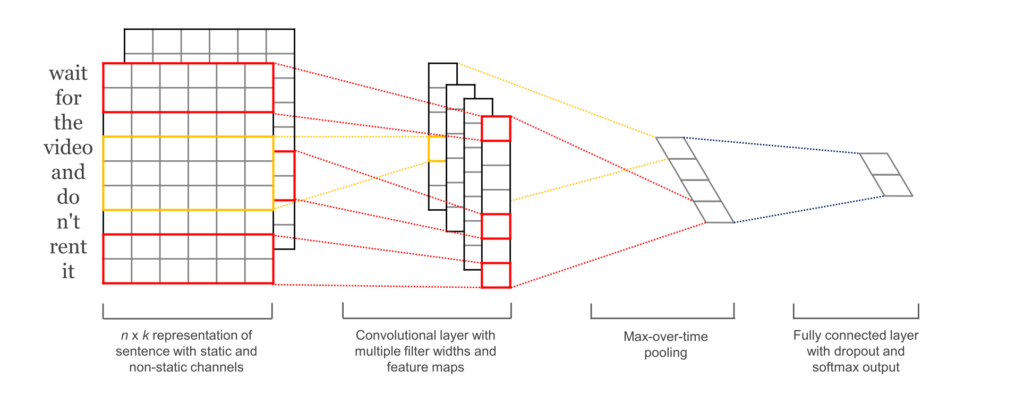
Convolutional Neural Networks (CNNs) are networks initially created for image-related tasks that can learn to capture specific features regardless of locality.
For a more concrete example of that, imagine we use CNNs to distinguish pictures of Cars vs. pictures of Dogs. Since CNNs learn to capture features regardless of where these might be, the CNN will learn that cars have wheels, and every time it sees a wheel, regardless of where it is on the picture, that feature will activate.
In our particular case, it could capture a negative phrase such as "don't like" regardless of where it happens in the tweet.
- I don't like watching those types of films
- That's the one thing I really don't like.
- I saw the movie, and I don't like how it ended.
LSTMs
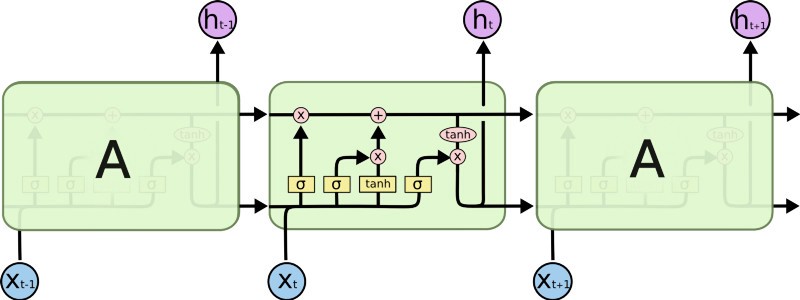
Long-Term Short Term Memory (LSTMs) are a type of network that has a memory that "remembers" previous data from the input and makes decisions based on that knowledge. These networks are more directly suited for written data inputs, since each word in a sentence has meaning based on the surrounding words (previous and upcoming words).
In our particular case, it is possible that an LSTM could allow us to capture changing sentiment in a tweet. For example, a sentence such as: At first I loved it, but then I ended up hating it. has words with conflicting sentiments that would end-up confusing a simple Feed-Forward network. The LSTM, on the other hand, could learn that sentiments expressed towards the end of a sentence mean more than those expressed at the start.
Twitter Data
The Twitter data used for this particular experiment was a mix of two datasets:
- The University of Michigan Kaggle competition dataset.
- The Neik Sanders Twitter Sentiment Analysis corpus.
In total these datasets contain 1,578,627 labeled tweets.
CNN-LSTM Model
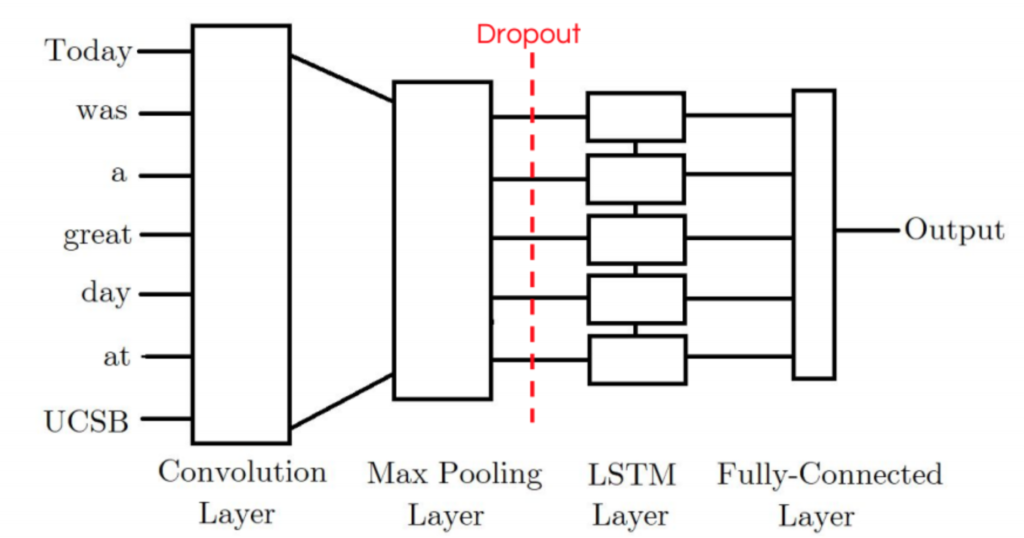
The first model I tried was the CNN-LSTM Model. Our CNN-LSTM model combination consists of an initial convolution
layer which will receive word embeddings as input. Its output will then be pooled to a smaller dimension which is then fed into an LSTM layer. The intuition behind this model is that the convolution layer will extract local features and the LSTM layer will then be able to use the ordering of said features to learn about the input’s text ordering. In practice, this model is not as powerful as our other LSTM-CNN model proposed.
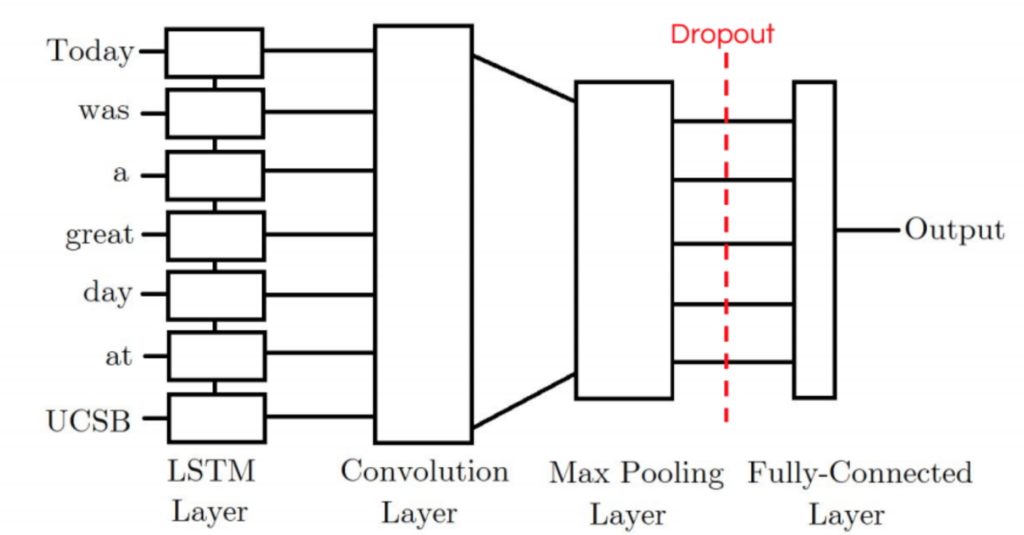
LSTM-CNN Model
Our CNN-LSTM model consists of an initial LSTM layer which will receive word embeddings for each token in the tweet as inputs. The intuition is that its output tokens will store information not only of the initial token, but also any previous tokens; In other words, the LSTM layer is generating a new encoding for the original input. The output of the LSTM layer is then fed into a convolution layer which we expect will extract local features. Finally the convolution layer’s output will be pooled to a smaller dimension and ultimately outputted as either a positive or negative label.
Results
We setup the experiment to use training sets of 10,000 tweets and testing sets of 2,500 labeled tweets.These training and testing sets contained equal amounts of negative and positive tweets. We re-did each test 5 times and reported on the average results of these tests.
We used the following parameters which we fine-tuned through manual testing:
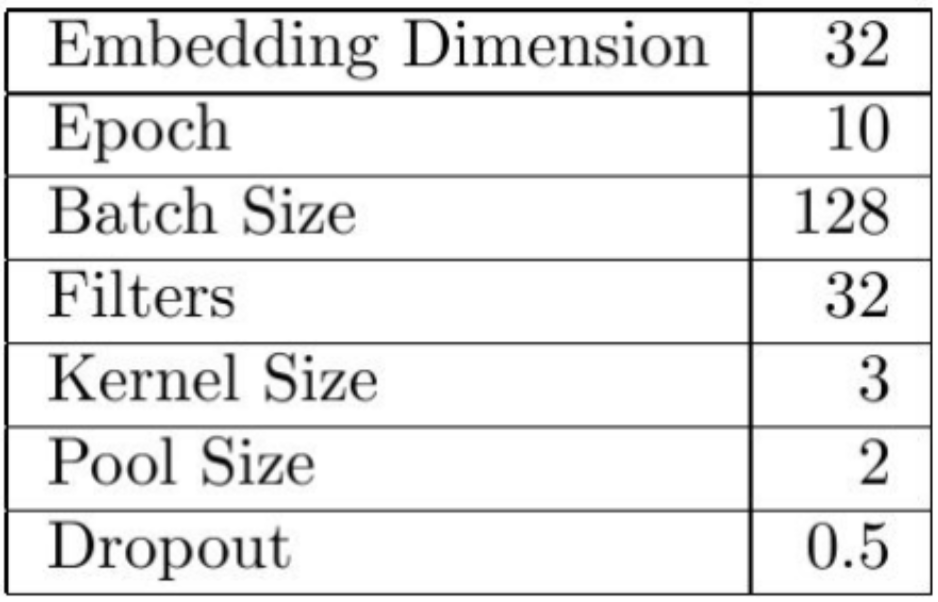
The actual results were as follows:
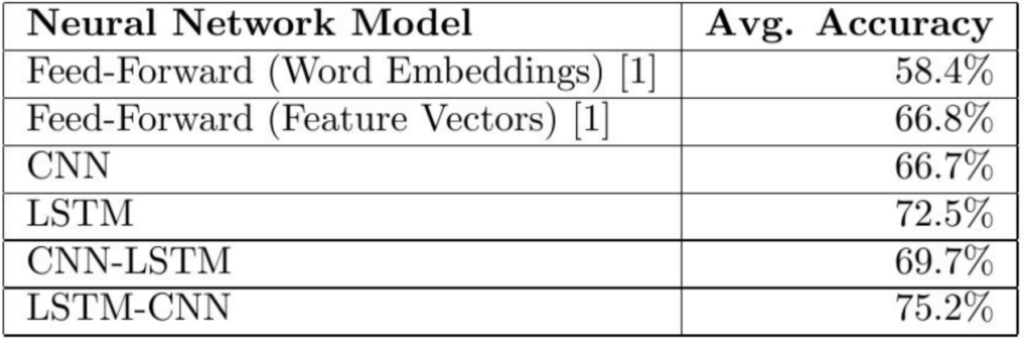
Our CNN-LSTM model achieved an accuracy of 3% higher than the CNN model, but 3.2% worse than the LSTM model. Meanwhile, our LSTM-CNN model performed 8.5% better than a CNN model and 2.7% better than an LSTM model.
These results seem to indicate that our initial intuition was correct, and that by combining CNNs and LSTMs we are able to harness both the CNN’s ability in recognizing local patterns, and the LSTM’s ability to harness the text’s ordering. However, the ordering of the layers in our models will play a crucial role on how well they perform.
We believe that the 5.5% difference between our models is not coincidental. It seems that the initial convolutional layer of our CNN-LSTM is loosing some of the text’s order / sequence information. Thus, if the order of the convolutional layer does not really give us any information, the LSTM layer will act as nothing more than just a fully connected layer. This model seems to fail to harness the full capabilities of the LSTM layer and thus does not achieve its maximum potential. In fact, it even does worse than a regular LSTM model.
On the other hand, the LSTM-CNN model seems to be the best because its initial LSTM layer seems to act as an encoder such that for every token in the input there is an output token that contains information not only of the original token, but all other previous tokens. Afterwards, the CNN layer will find local patterns using this richer representation of the original input, allowing for better accuracy.
Further Observations
Some of the observations I made during the testing (and which are explained in much more detail on the paper):
Learning Rates
CNN & CNN-LSTM models need more epochs to learn and overfit less quickly, as opposed to LSTM & LSTM-CNN models.

Drop Rates
This wasn't so much of a surprise, but I did notice that it is very important to add a Dropout layer after any Convolutional layer in both the CNN-LSTM and LSTM-CNN models.
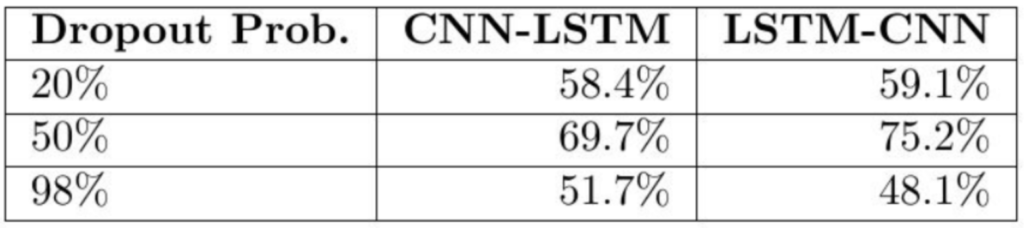
(Note: in this case Dropout Prob. is how likely we are to drop a random input.)
Pre-Trained Word Embeddings
I attempted to use pre-trained word embeddings, as opposed to having the system learn the word embeddings form our data. Surprisingly using these pre-trained GloVe word embeddings gave us worst accuracy. I believe this might be due to the fact that twitter data contains multiple misspellings, emojis, mentions, and other twitter-specific text irregularities that weren't taken into consideration when building the GloVe embeddings.

Conclusions & Future Work
In terms of future work, I would like to test other types of LSTMs (for example Bi-LSTMs) and see what effects this has on the accuracy of our systems. It would also be interesting to find a better way to deal with misspellings or other irregularities found on twitter language. I believe this could be achieved by building Twitter specific word-embeddings. Lastly, it would be interesting to make use of Twitter specific features, such as # of retweets, likes, etc. to feed along the text data.
On a personal note, this project was mainly intended as an excuse to further understand CNN and LSTM models, along with experimenting with Tensorflow. Moreover, I was happy to see that these two models did much better than our previous (naive) attempts.
As always, the source code and paper are publicly available: paper & code. If you have any questions or comments feel free to reach out. Happy coding! 🙂
Awesome post! So did you create the NN model from scratch or did you use an existing NN layout?
Also, how long did it take you to develop this solution? I am in the process of learning ML too, and have gone through the excellent course by Andrew Ng on coursera. However it doesn't touch on Tensorflow or Keras, so weirdly I have more difficulty using these higher-level libraries than just NumPy! Do you have any recommendations on how you approached going from a learning phase to developing something like this?
Thanks and keep up the great work!
I wish I had a good answer for this, but the truth is that I spent a lot of time just googling "Tensorflow/Keras Tutorials" (e.g. Adventures In Machine Learning Tuts, Elite Data Science Keras Tuts, Official Tensorflow Docs, Machine Learning Mastery Keras Tuts, etc.) I've recently heard good things from this book: "Hands-On Machine Learning with Scikit-Learn & Tensorflow", but I haven't had time to check it out. Hope this helps! 🙂
edit: To answer your first question, I based my designs on standard CNN/LSTM models that you can find online, however the coding and merging of the two was done by me. So in a way I didn't build them completely from scratch.
Could you post the code?
Code is posted at my Github repo: https://github.com/pmsosa/CS291K
good article, amazing code on github, thanks for sharing
Could you please upload the DataSet used in this work?
and any suggestions to improve it.
There is a bunch of different datasets that you can find online, but the two I used were:
- https://inclass.kaggle.com/c/si650winter11
- http://www.sananalytics.com/lab/twitter-sentiment/
Hi Pedro! Thank you for sharing your interesting idea!
A few points:
- your dataset is really small and results might have a high variance
- no pre-trained word embedding equals most certainly to a higher variance
- in the CNN/LSTM version, we could easily use a 5 or 7 filters (n-grams)
Intuitively, CNN/LSTM should be superior to LSTM/CNN. But my intuition is often wrong. I'll put it on my to-do-and-test list
Thanks again
Thanks for the input!
I'll have to run a couple more experiments using bigger dataset and larger filters.
As for the word embeddings, I did try both with and without pre-trained embeddings and definitely saw a difference in their performance.
Let me know what you find if you get a chance to test out other parameter variations. 🙂
Hi Pedro,
Good article. If you will humor me for a bit as a devil's advocate -
.1. Your initial intuition doesn't align with the results you observed, namely cnn+lstm should have out performed lstm+cnn (agree with Franco here). One wild guess is that it's just tuned architecture (you got lucky) in one case versus not in case you didn't spend time tuning both architectures. Second, embeddings (CBOW or skip-gram) essentially capture local context of words around it, which is somewhat equivalent to what the convolutional layers in the lower layers would accomplish. So, maybe you want the CNN filters to be longer to capture even longer context?
2. It's probably the pooling layer after convolution that destroys the locality in the CNN. You could retry without that layer in your CNN+LSTM network.
3. I'm still struggling to think how the convolution layer on top of the LSTM layer is adding value. For example, if you replace the CNN by a fully connected layer(s), do you get the same benefit as the CNN layers.
4. Curious to know if you have a published baseline to compare against? Namely, are you actually outperforming a carefully tuned LSTM with an LSTM+CNN combi?
good article and good work
could you please post the data and the embeddings you used.
Thanks for the kind words!
Datasets:
- https://inclass.kaggle.com/c/si650winter11
- http://www.sananalytics.com/lab/twitter-sentiment/
Word Embeddings (GLoVE):
- https://nlp.stanford.edu/projects/glove/
Great article. Very insightful..
I've trained a dataset from the Stanford SNLI project (https://nlp.stanford.edu/projects/snli/) with 180k sentence pairs labeled with 1 or 0 depending on if they have similar meaning..
I've got ~85% accuracy, but I'm struggling to understand how I can use the restored model to build a simple command line interface to evaluate 2 generic sentences in terms of semantic similarity.
Any advice is greatly appreciated
Hi Dan,
I haven't touched the code in a bit, so I apologize beforehand for being a bit rusty on it. If you want to build a command-line tool to just evaluate sentences, here are some tips on how to get that going:
- The Evaluation step is actually running on the dev_step(x_dev, y_dev, writer=dev_summary_writer) function.
- After training the model you could simply code at the end some simple logic to take in an x_dev = your batch of sentences, and y_dev = your expected results.
- If you don't have expected results you could simply slightly modify the dev_step to simply print whatever the outcome of the generic sentences was
- You might already be familiar with this, but I highly recommend debugging this using IPython's embed function. It let's you essentially place a breakpoint anywhere in the code so you can print variables, run code, etc.
Hit me up if you have any other questions! 🙂
Hello!
Thank you for writing this blog and paper! I have one question about the coed in lstm_cnn.py. In line 26 you the output is "self.lstm_out" and "self.lstm_state". However, the state variable is not used later on. Is this they way it should work or this a small error?
Thank you!
Thank you! Very helpful article! I learned a lot